Qwen3-235B-A22B-Thinking-2507
综合介绍
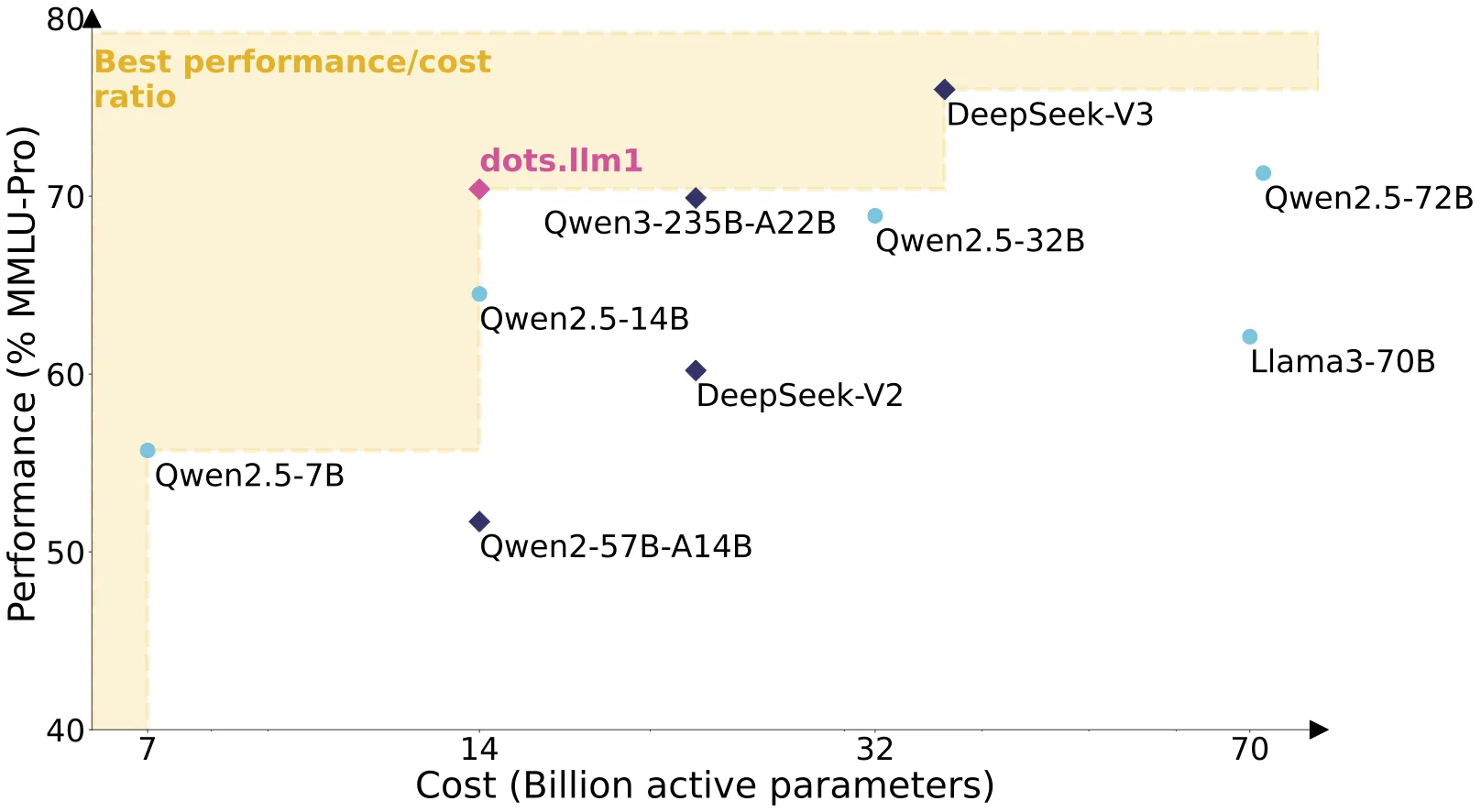
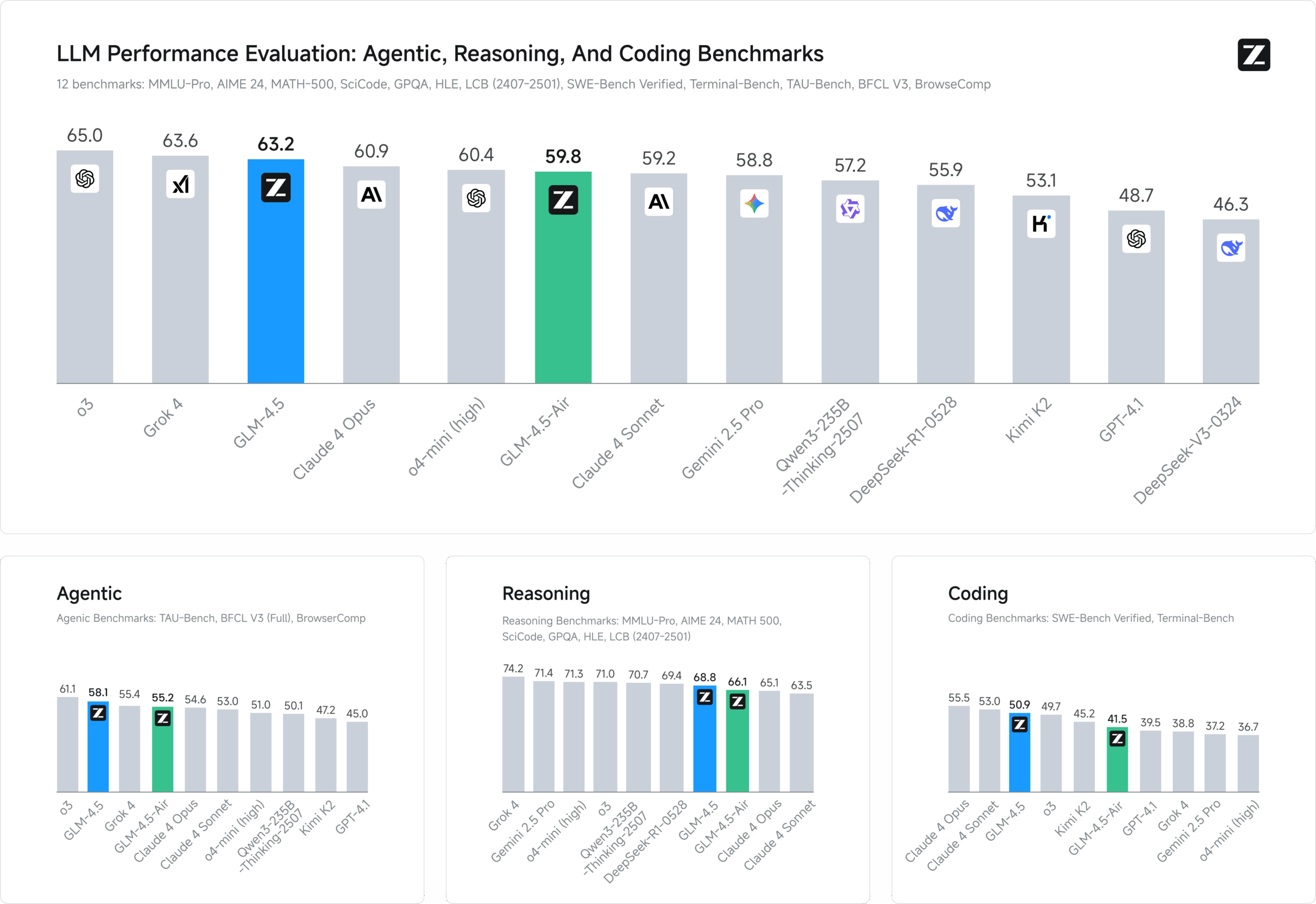
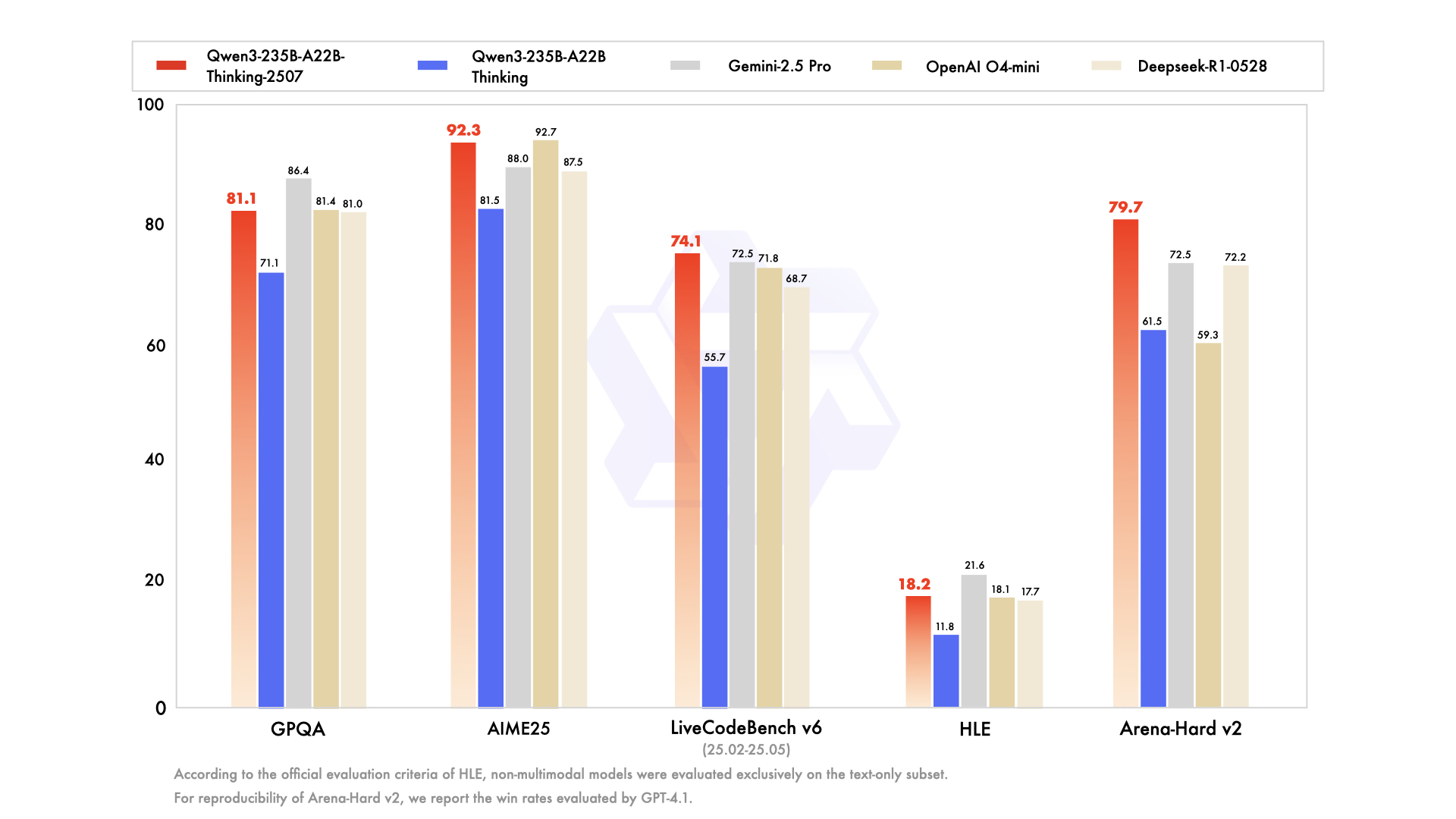
Qwen3-235B-A22B-Thinking-2507 是由阿里巴巴通义千问团队开发的开源大语言模型。 它采用了混合专家(MoE)架构,总参数量达到2350亿,但在处理具体任务时,模型只会激活其中的220亿参数。 这种设计既保证了模型强大的处理能力,又提高了运行效率。该模型的核心特色是其“深度思考”能力,专门用于处理需要复杂、多步骤推理的任务,例如数学解题、科学分析、逻辑推理和编写代码。 相比之前的版本,它在推理能力、遵循指令、使用工具以及理解超长文本(支持25.6万字符长度的上下文)方面都有了显著的提升。 根据多项行业基准测试,它的性能在开源模型中处于领先水平,并且可以和一些顶尖的闭源模型相媲美。
功能列表
- 复杂推理能力: 专门为需要深度思考和逻辑分析的任务进行优化,在数学、科学、编程和逻辑推理等领域表现出色。
- 混合专家模型(MoE): 总参数量为2350亿,每次运行时仅激活220亿参数,实现了性能和效率的平衡。
- 超长上下文支持: 模型原生支持长达262,144个字符的上下文窗口,可以处理和理解非常长的文档或对话历史。
- “思考”模式: 模型在输出最终答案前,会生成一个内部的思考过程。这个过程被包裹在
</think>标签内,让用户可以了解模型是如何一步步得出结论的。 - 强大的工具调用(Agent)能力: 模型在作为智能体(Agent)核心时表现优异,能有效理解并调用外部工具或函数来完成复杂任务。
- 多语言支持: Qwen3系列模型支持包括中文在内的多种语言。
- 开源和易于部署: 模型是开源的,提供了详细的部署指南,支持在多种主流框架如Transformers、vLLM和Ollama上运行。
使用帮助
Qwen3-235B-A22B-Thinking-2507模型主要面向需要深度思考能力的开发者和研究人员。它的使用方式根据不同的应用场景和技术环境有所区别。
基本环境配置
在开始使用模型前,你需要一个支持Python的环境,并安装Hugging Face的transformers库。建议使用最新版本以获得最佳兼容性。
pip install --upgrade transformers
快速上手:使用Transformers库进行推理
这是最基础的本地调用方式。通过几行代码,你就可以加载模型并进行文本生成。
- 加载模型和分词器:首先,你需要从Hugging Face Hub加载模型和对应的分词器。请确保你的设备有足够的内存和计算能力(如高性能GPU)来承载模型。
from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "Qwen/Qwen3-235B-A22B-Thinking-2507" # 加载分词器 tokenizer = AutoTokenizer.from_pretrained(model_name) # 加载模型,建议使用自动设备映射来分配资源 model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", # 自动选择精度,如BF16 device_map="auto" # 自动将模型分层加载到不同GPU和CPU内存中 ) - 准备输入内容:该模型使用特定的聊天模板。当你输入一个问题时,
apply_chat_template会自动添加<think>标签,引导模型进入思考模式。prompt = "请给我简要介绍一下大型语言模型。" messages = [ {"role": "user", "content": prompt} ] # 应用聊天模板 text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, ) model_inputs = tokenizer([text], return_tensors="pt").to(model.device) - 生成文本并解析输出:模型生成的内容会包含思考过程和最终答案。你需要对输出进行解析,以区分这两部分。思考过程通常以
</think>标签结束。# 生成回复,可以设置最大生成长度 generated_ids = model.generate( **model_inputs, max_new_tokens=32768 ) # 从生成结果中移除输入部分 output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # 解析思考过程和最终内容 try: # 寻找</think>标签的位置 index = len(output_ids) - output_ids[::-1].index(151668) except ValueError: index = 0 # 如果没有找到标签,则认为全部是内容 thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip() content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip() print("模型的思考过程:", thinking_content) print("最终的回复内容:", content)
高性能部署
对于生产环境或需要处理高并发请求的场景,建议使用vLLM或SGLang等推理优化框架。
- 使用vLLM部署:
vLLM是一个高效的推理服务框架。你可以使用以下命令启动一个兼容OpenAI API的推理服务器。vllm serve Qwen/Qwen3-235B-A22B-Thinking-2507 \ --tensor-parallel-size 8 \ --max-model-len 262144 \ --enable-reasoning \ --reasoning-parser deepseek_r1--tensor-parallel-size 8: 表示使用8个GPU进行张量并行,需要根据你的硬件配置调整。--max-model-len 262144: 设置最大上下文长度。如果遇到内存不足(OOM)问题,可以适当减小此值,但官方建议至少保持在131,072以上以保证推理效果。
Agent(智能体)应用
该模型强大的工具调用能力使其非常适合用于构建AI Agent。官方推荐使用Qwen-Agent框架来简化开发。
- 安装Qwen-Agent:
pip install qwen-agent - 定义工具并运行Agent:
Qwen-Agent可以方便地集成代码解释器、网络搜索等内置工具,也可以自定义外部工具。from qwen_agent.agents import Assistant # 配置LLM,这里使用一个兼容OpenAI的本地API端点 llm_cfg = { 'model': 'Qwen3-235B-A22B-Thinking-2507', 'model_server': 'http://localhost:8000/v1', # vLLM部署的地址 'api_key': 'EMPTY', } # 定义要使用的工具列表 tools = ['code_interpreter'] # 使用内置的代码解释器 # 创建Agent bot = Assistant(llm=llm_cfg, function_list=tools) # 运行Agent messages = [{'role': 'user', 'content': '计算1024乘以1024的结果'}] for responses in bot.run(messages=messages): print(responses)在这个例子中,Agent会自动调用代码解释器来执行计算,而不是仅仅在模型内部进行数学运算,从而获得更精确的结果。
应用场景
- 科学研究与学术分析研究人员可以利用模型超长的上下文能力,输入整篇或多篇学术论文,让模型进行摘要、信息提取、文献综述或对复杂理论进行分析和解读。
- 软件开发与代码生成开发者可以利用模型强大的代码能力和Agent功能,构建智能编程助手。这个助手不仅能编写代码片段,还能理解整个项目的上下文,进行调试、重构,甚至自主完成从需求分析到代码实现的全过程。
- 复杂金融或法律文档解读在金融和法律领域,专业人士需要处理大量冗长且复杂的文档。模型可以帮助他们快速提炼合同要点、分析财报数据、发现风险条款,大幅提升工作效率。
- 多语言内容创作与翻译对于需要处理多种语言的跨国公司或内容创作者,模型可以提供高质量的翻译和本地化内容创作服务,确保信息在不同文化背景下都能被准确传达。
QA
- 这个模型和它的“Instruct”版本有什么区别?
Thinking版本(即本文介绍的模型)专门为复杂的、需要多步推理的任务设计,它会先思考再回答。 而Instruct版本则为“非思考”模式,专注于快速、直接地响应用户指令,适用于问答、聊天等即时交互场景。 - 使用这个模型需要什么样的硬件?作为一个拥有2350亿参数的大模型,即使采用了MoE架构,它仍然需要强大的硬件支持,通常是多张高端服务器级GPU。例如,使用vLLM部署时,官方示例中使用了8个GPU。 普通的个人电脑无法直接运行此模型。
- 模型输出的
</think>标签是什么意思?这是模型“思考”过程的标记。 在这个标签出现之前的内容是模型的“内心独白”或推理步骤,它展示了模型是如何分析问题并构建答案的。标签之后的内容是它认为的最终答案。这种设计有助于提高复杂任务的准确性,并增加模型决策的透明度。 - 模型是免费使用的吗?模型本身是开源的,可以免费下载和使用,但需要遵守其
apache-2.0开源许可证。 不过,运行这个模型所需的计算资源(如GPU服务器)会产生相应的成本。